
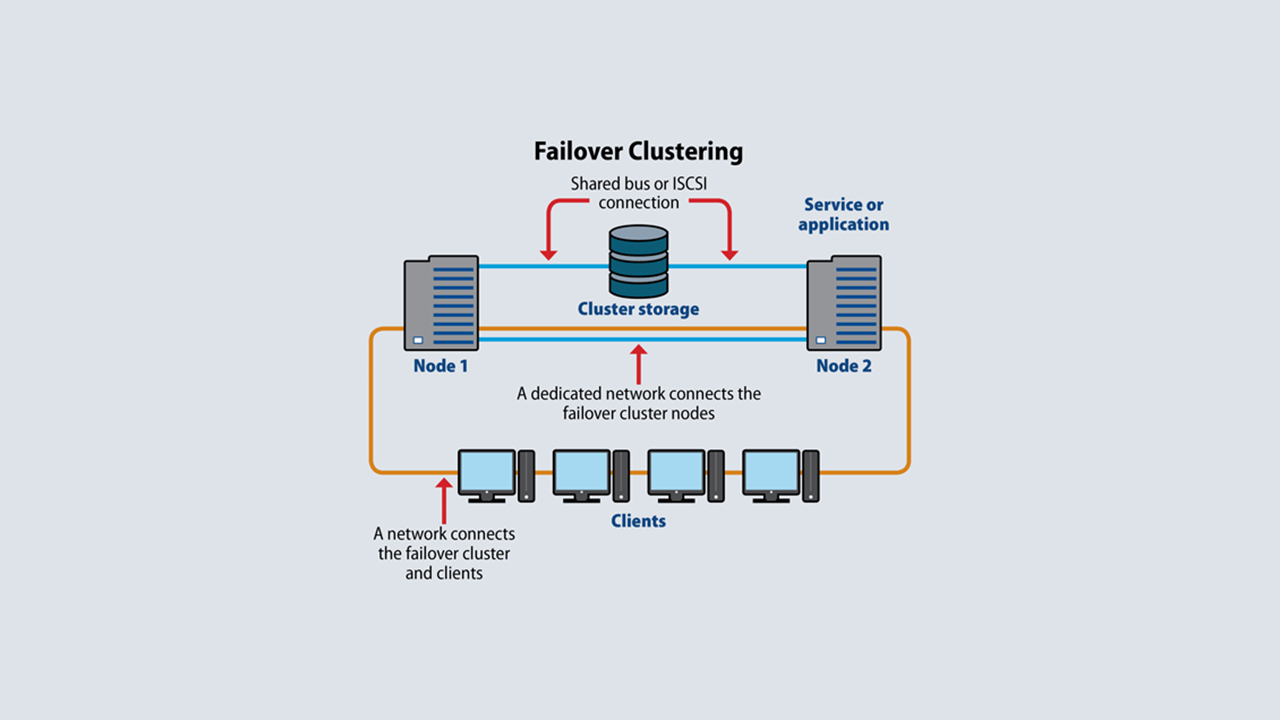
Server clustering is a pivotal technology in modern computing, offering enhanced performance, reliability, and scalability by connecting multiple servers to function as a unified system. This configuration ensures that if one server encounters an issue, others can seamlessly take over, maintaining uninterrupted service.
Understanding Server Clustering
At its core, server clustering involves linking multiple independent servers, known as nodes, to operate cohesively. Each node runs its own instance of an operating system and applications, but they work together to provide a single, unified service. This setup is designed to enhance system availability, performance, and scalability.
Key Benefits of Server Clustering
A. High Availability: One of the primary advantages of server clustering is its ability to provide high availability. If a node fails, the clustering software detects the failure and automatically shifts the workload to another node, ensuring continuous service without manual intervention.
B. Scalability: Server clusters allow organizations to scale their computing resources efficiently. As demand increases, additional nodes can be added to the cluster to handle the increased workload, ensuring optimal performance.
C. Load Balancing: Clustering enables effective distribution of workloads across multiple nodes. This load balancing ensures that no single server becomes a bottleneck, optimizing resource utilization and enhancing overall system performance.
D. Fault Tolerance: In the event of hardware or software failures, server clusters provide fault tolerance by redistributing tasks to operational nodes, minimizing downtime and preventing data loss.
E. Improved Resource Utilization: By pooling resources from multiple servers, clusters can optimize resource utilization, ensuring that computing power, memory, and storage are used efficiently across the system.
Types of Server Clusters
A. High-Availability (HA) Clusters: Designed to maintain service continuity, HA clusters automatically redirect workloads to functioning nodes in case of a failure, minimizing downtime.
B. Load-Balancing Clusters: These clusters distribute incoming requests evenly across multiple nodes, ensuring no single server is overwhelmed and enhancing system responsiveness.
C. High-Performance Clusters: Utilized for computation-intensive tasks, these clusters combine the power of multiple servers to perform complex calculations, often used in scientific research and data analysis.
Implementing a Server Cluster
Setting up a server cluster involves several critical steps to ensure optimal performance and reliability:
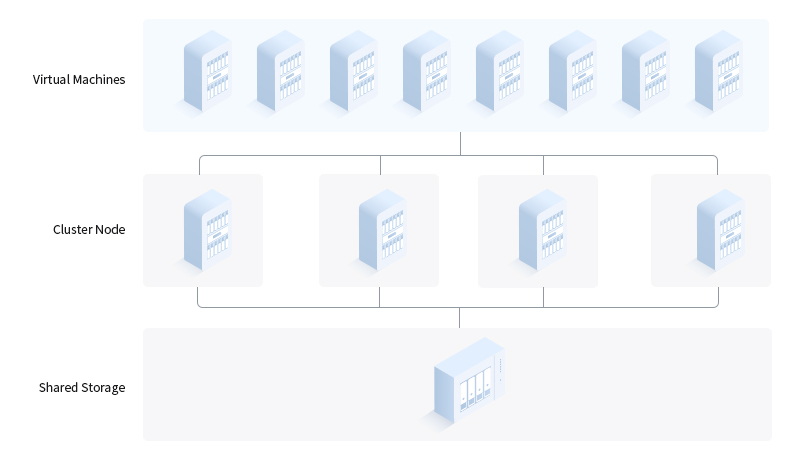
A. Hardware Selection: Choose compatible servers with similar configurations to ensure seamless integration and performance consistency across the cluster.
B. Networking: Establish a robust and high-speed network infrastructure to facilitate efficient communication between nodes, which is essential for synchronization and load balancing.
C. Storage Configuration: Implement shared storage solutions, such as Storage Area Networks (SANs) or Network-Attached Storage (NAS), to allow nodes to access common data repositories, ensuring data consistency and availability.
D. Clustering Software Installation: Deploy clustering software that manages node communication, workload distribution, and failover processes. Options include open-source solutions like Linux-HA or proprietary software like Microsoft Cluster Server.
E. Testing and Monitoring: Conduct thorough testing to identify potential issues and implement monitoring tools to oversee cluster performance, ensuring timely detection and resolution of problems.
Challenges and Considerations
While server clustering offers numerous benefits, it’s essential to address potential challenges:
A. Complexity: Implementing and managing a cluster can be complex, requiring specialized knowledge and careful planning.
B. Cost: The initial investment in hardware, software, and networking infrastructure can be significant.
C. Maintenance: Regular maintenance is necessary to ensure all nodes are updated and functioning correctly, which can be resource-intensive.
D. Data Consistency: Ensuring data consistency across nodes, especially in active-active configurations, requires meticulous synchronization mechanisms.












