
In today’s digital landscape, server uptime plays a crucial role in determining the reliability and success of online businesses. Whether you run an e-commerce website, a SaaS platform, or a corporate portal, ensuring consistent server uptime is essential for customer satisfaction, SEO rankings, and overall business performance. This article explores the importance of server uptime, the key metrics involved, and the best practices for optimizing uptime to maximize profitability and user experience.
What is Server Uptime?
Server uptime refers to the percentage of time a server remains operational and accessible over a given period. It is a key performance indicator (KPI) used to measure the reliability and stability of web hosting services, cloud computing platforms, and dedicated servers.
A high uptime percentage signifies that a website or application remains accessible to users without interruptions, ensuring smooth operation and preventing revenue loss. The industry standard for uptime is 99.9% or higher, which translates to minimal downtime per year.
Why Server Uptime is Crucial
Server uptime is fundamental to business success in the digital world. Here are the key reasons why uptime matters:
A. Improves User Experience
A website that experiences frequent downtime frustrates users, leading to higher bounce rates and a negative reputation. Ensuring high uptime guarantees seamless navigation and improved engagement.
B. Enhances SEO Rankings
Search engines like Google prioritize websites with high availability. Frequent downtime can negatively impact search rankings, reducing organic traffic and potential conversions.
C. Boosts Revenue and Sales
E-commerce sites and subscription-based services depend on uptime to drive sales. Even minor downtime can result in significant revenue losses, making uptime optimization crucial.
D. Strengthens Brand Trust
Users expect reliability when accessing websites and online services. Prolonged downtime can damage credibility and customer trust, leading to long-term losses.
E. Ensures Compliance with SLAs
Many businesses operate under Service Level Agreements (SLAs) that define acceptable uptime levels. Failure to meet SLA requirements can lead to penalties and legal implications.
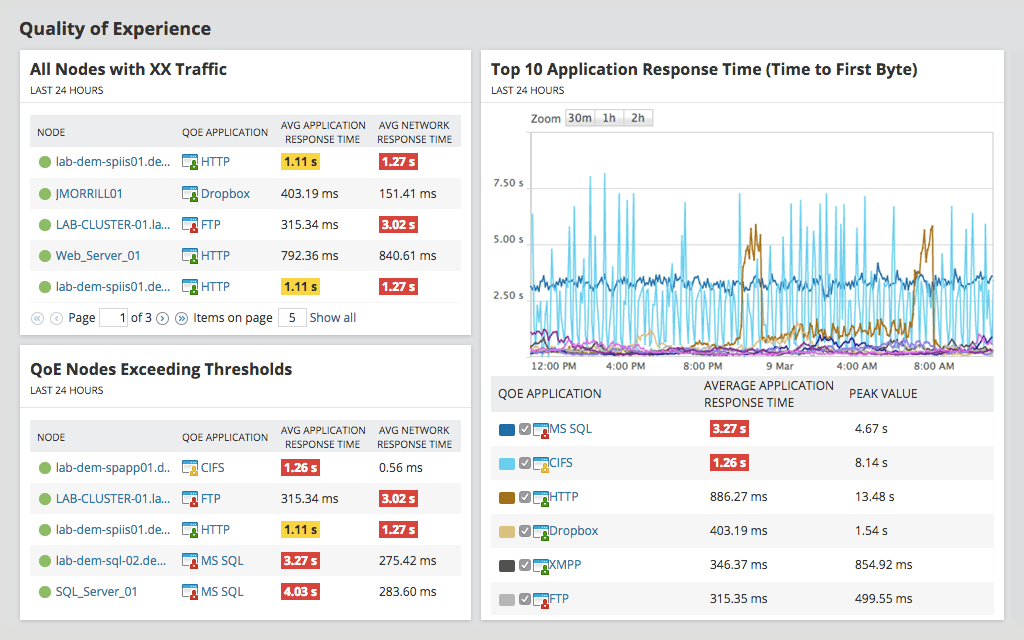
Key Metrics for Measuring Server Uptime
Monitoring and measuring uptime requires specific metrics to assess server performance accurately. Below are the most critical uptime metrics:
A. Uptime Percentage
- Calculated as (Total Uptime / Total Time) × 100.
- Industry standard uptime guarantees range from 99.9% to 99.999% (Five Nines Availability).
B. Mean Time Between Failures (MTBF)
- Represents the average time between system failures.
- A higher MTBF indicates a more reliable server infrastructure.
C. Mean Time to Repair (MTTR)
- Measures the average time taken to restore a server after a failure.
- A lower MTTR minimizes downtime impact on users.
D. Response Time
- Refers to the time taken by a server to respond to a user request.
- Slow response times indicate potential server performance issues.
E. Error Rate
- Tracks the percentage of failed requests over a specific period.
- A high error rate signals underlying server instability.
Best Practices for Maximizing Server Uptime
Maintaining high uptime requires strategic measures to prevent outages and optimize performance. Implementing the following best practices ensures continuous availability:
A. Choose a Reliable Hosting Provider
- Opt for providers that guarantee 99.9% uptime or higher.
- Research customer reviews and SLA agreements before committing.
B. Implement Redundancy and Failover Systems
- Use backup servers to take over in case of failure.
- Deploy load balancing to distribute traffic efficiently.
C. Monitor Server Performance Regularly
- Use tools like Pingdom, UptimeRobot, and Nagios for real-time monitoring.
- Set up alerts for potential downtime incidents.
D. Optimize Website and Server Performance
- Implement caching techniques to reduce server load.
- Use a Content Delivery Network (CDN) to improve global availability.
E. Keep Software and Security Updates Up to Date
- Regularly update operating systems, web applications, and plugins.
- Patch security vulnerabilities to prevent cyberattacks.
F. Invest in High-Quality Hardware
- Choose enterprise-grade hardware with failover capabilities.
- Ensure data centers have backup power supplies and cooling systems.
G. Develop a Disaster Recovery Plan
- Establish backup protocols and data recovery strategies.
- Test recovery procedures to ensure quick restoration during failures.
H. Leverage Cloud-Based Solutions
- Cloud hosting providers offer scalable and redundant infrastructure.
- Choose reputable cloud services like AWS, Google Cloud, or Microsoft Azure.
Common Causes of Downtime and How to Prevent Them
Understanding the common causes of server downtime helps in proactive prevention:
A. Hardware Failures
- Preventative measure: Invest in redundant hardware and data backups.
B. Software Bugs and Updates
- Preventative measure: Test software updates in a staging environment before deployment.
C. Cybersecurity Attacks (DDoS, Malware, Hacks)
- Preventative measure: Use firewalls, DDoS protection, and secure authentication methods.
D. Human Errors
- Preventative measure: Implement strict access controls and staff training.
E. Network Outages
- Preventative measure: Use multiple ISPs and failover networks.
F. Power Failures
- Preventative measure: Ensure data centers have backup power generators.











